集群的启动以及部署
kubectl
Kubernetes 命令行工具
kubectl允许您对 Kubernetes 集群运行命令。您可以使用 kubectl 部署应用程序、检查和管理集群资源以及查看日志。有关更多信息(包括 kubectl 操作的完整列表),请参阅
kubectl参考文档。
kubectl 可安装在多种 Linux 平台、macOS 和 Windows 系统上。请在下方查找您偏好的操作系统。
minikube
https://minikube.sigs.k8s.io/docs/start/?arch=%2Fwindows%2Fx86-64%2Fstable%2F.exe+download#Service
先下载对应的安装包进行安装
minikube 是本地 Kubernetes,专注于让 Kubernetes 的学习和开发变得容易。
您只需要一个 Docker(或类似兼容的)容器或虚拟机环境,即可通过一条命令部署 Kubernetes:minikube start
在具有管理员权限(但未以 root 用户身份登录)的终端中运行:
minikube start如果 minikube 启动失败,请参阅 驱动程序页面,以获取有关设置兼容容器或虚拟机管理器的帮助。
# 如果遇到镜像拉取失败的,让 minikube 里的 Docker daemon 也能走代理,把镜像拉下来。 # 以 Clash 为例,默认 127.0.0.1:7890 # 设置 minikube 使用主机 SOCKS5 minikube delete # 清掉之前失败的缓存 minikube start --driver=hyperv --docker-env HTTP_PROXY=socks5://host.minikube.internal:7890 ` --docker-env HTTPS_PROXY=socks5://host.minikube.internal:7890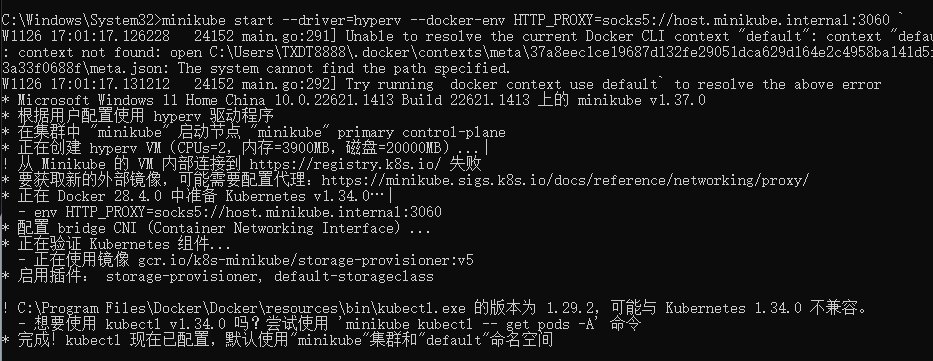
拉取镜像 暴露端口
# 拉镜像并启动容器
kubectl create deployment hello-minikube --image=kicbase/echo-server:1.0
# 使用 NodePort 暴露端口, --port=8080 对应服务内部的端口
kubectl expose deployment hello-minikube --type=NodePort --port=8080
- 可能需要一些时间,但运行以下命令后,您的部署很快就会显示出来:
kubectl get services hello-minikube

这代表服务映射到了该容器内部的的 32338 端口
- 访问此服务的最简单方法是让 minikube 为您启动一个 Web 浏览器:
minikube service hello-minikube
- 或者,可以使用 kubectl 进行端口转发:
kubectl port-forward service/hello-minikube 7080:8080
# 把你 本地电脑(Windows)的 7080 端口 转发到 Kubernetes 集群里的 Service hello-minikube 的 8080 端口。
您的应用程序现在可以在 http://localhost:7080/ 上访问。
管理你的集群
暂停 Kubernetes 而不影响已部署的应用程序:
minikube pause
恢复已暂停的实例:
minikube unpause
停止集群:
minikube stop
更改默认内存限制(需要重启):
minikube config set memory 9001
浏览易于安装的 Kubernetes 服务目录:
minikube addons list
创建第二个集群,运行旧版本的 Kubernetes:
minikube start -p aged --kubernetes-version=v1.34.0
删除所有minikube集群:
minikube delete --all
eyJhbGciOiJSUzI1NiIsImtpZCI6Ik5kcmRfcWo0RGRLSUI0Y3I1bXFLNm9aeUJoNjRvbHQzdFMwcG9KRmYtbk0ifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIj
oxNzk1Njg3Nzg4LCJpYXQiOjE3NjQxNTE3ODgsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwianRpIjoiMDgxN2QyYTUtMjIxZC00NzUxLWE4ZDctZDUyMTZlMzAwZWFmIiwia3V
iZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbi11c2VyIiwidWlkIjoiZGI4MGZhM2ItZTcxOC00ODIxLTg1YWUtNTE2M2Q5MWNhZWU0
In19LCJuYmYiOjE3NjQxNTE3ODgsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbi11c2VyIn0.wgv1-JvoLJBlsHMLaYyyTz0X9_luIwpNRdzcVVxu0cmK1L47X3mvL5T3YXKsX
2B-Ny8LatAnx_-Z0-HiTCh-KXigSZ6twqqsnNvb9MRnIfBoiGZcD2yL0tjFJoIVVSJLfJphfZSMtQC_cAvDt_tURwb4Wn9SGy5ZrgCwXdHnthmAapfNFtEWg167quMCoOYoycrk-MAlAiL4dNPaKaLQFb747sHCFFhTSsFd-snf1b
yP23MORxGF1gCT3iysrJ91pSknOTm9FCSjb6SiTCGR90k43yEpZ6787C--GZUyfpeFoa7HjWSlSzU77P-RE4SlGjYFKPynghK3vBPKMhI3TQ
配置 Pods 以及 容器
为容器和 Pod 分配内存资源
该页面上的一些步骤要求你在集群中运行 metrics-server 服务。 如果你已经有在运行中的 metrics-server,则可以跳过这些步骤。
如果你运行的是 Minikube,可以运行下面的命令启用 metrics-server:
minikube addons enable metrics-server
要查看 metrics-server 或资源指标 API (metrics.k8s.io) 是否已经运行,请运行以下命令:
kubectl get apiservices
- 创建命名空间
创建一个命名空间,以便将本练习中创建的资源与集群的其余部分隔离。
kubectl create namespace mem-example
# 你也可以改成自己想要的命名空间名字 这里 mem-example 我改成了 waite
- 指定内存请求以及限制
要为容器指定内存请求,请在容器资源清单中包含 resources: requests 字段。 同理,要指定内存限制,请包含 resources: limits。
在本练习中,你将创建一个拥有一个容器的 Pod。 容器将会请求 100 MiB 内存,并且内存会被限制在 200 MiB 以内。 这是 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: waite
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
requests:
memory: "100Mi"
limits:
memory: "200Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
配置文件的 args 部分提供了容器启动时的参数。 "--vm-bytes", "150M" 参数告知容器尝试分配 150 MiB 内存。
- 开始创建 Pod (注意运行在同级目录)
kubectl apply -f memory-request-limit.yaml --namespace=waite
- 验证 Pod 中的容器是否已运行
kubectl get pod memory-demo --namespace=waite
kubectl get pod -n waite
- 查看 Pod 相关的详细信息:
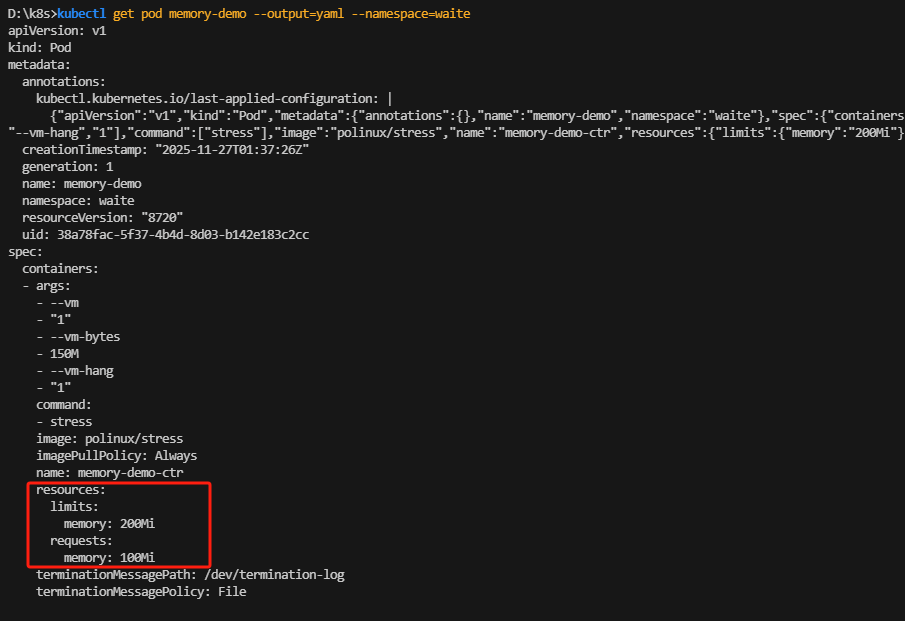
kubectl get pod memory-demo --output=yaml --namespace=waite
输出结果显示:该 Pod 中容器的内存请求为 100 MiB,内存限制为 200 MiB。
- 运行
kubectl top命令,获取该 Pod 的指标数据, 输出结果显示:Pod 正在使用的内存大约为 150 MiB。 这大于 Pod 请求的 100 MiB,但在 Pod 限制的 200 MiB之内。
kubectl top pod memory-demo --namespace=waite
NAME CPU(cores) MEMORY(bytes)
memory-demo 76m 150Mi
- 删除 pod
kubectl delete pod memory-demo --namespace=waite
当节点拥有足够的可用内存时,容器可以使用其请求的内存。 但是,容器不允许使用超过其限制的内存。 如果容器分配的内存超过其限制,该容器会成为被终止的候选容器。 如果容器继续消耗超出其限制的内存,则终止容器。 如果终止的容器可以被重启,则 kubelet 会重新启动它,就像其他任何类型的运行时失败一样。
在本练习中,你将创建一个 Pod,尝试分配超出其限制的内存。 这是一个 Pod 的配置文件,其拥有一个容器,该容器的内存请求为 50 MiB,内存限制为 100 MiB:
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-2
namespace: waite
spec:
containers:
- name: memory-demo-2-ctr
image: polinux/stress
resources:
requests:
memory: "50Mi"
limits:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
在配置文件的 args 部分中,你可以看到容器会尝试分配 250 MiB 内存,这远高于 100 MiB 的限制。
kubectl apply -f memory-request-limit.yaml --namespace=waite
D:\k8s>kubectl get pod memory-demo-1 --namespace=waite
NAME READY STATUS RESTARTS AGE
memory-demo-1 0/1 OOMKilled 5 (107s ago) 3m32s
D:\k8s>kubectl get pod memory-demo-1 --namespace=waite
NAME READY STATUS RESTARTS AGE
memory-demo-1 0/1 CrashLoopBackOff 5 (17s ago) 3m35s
# 容器反复重启又崩溃
D:\k8s>kubectl get pod memory-demo-1 --output=yaml --namespace=waite
......
lastState:
terminated:
containerID: docker://718a86ad475ac286f097a31b6dd678aa2656d05df63fdb27aae32658b7ca19a6
exitCode: 1
finishedAt: "2025-11-27T01:52:34Z"
reason: OOMKilled
startedAt: "2025-11-27T01:52:34Z"
# 输出结果显示:由于内存溢出(OOM),容器已被杀掉
内存请求和限制是与容器关联的,但将 Pod 视为具有内存请求和限制,也是很有用的。 Pod 的内存请求是 Pod 中所有容器的内存请求之和。 同理,Pod 的内存限制是 Pod 中所有容器的内存限制之和。
Pod 的调度基于请求。只有当节点拥有足够满足 Pod 内存请求的内存时,才会将 Pod 调度至节点上运行。
在本练习中,你将创建一个 Pod,其内存请求超过了你集群中的任意一个节点所拥有的内存。 这是该 Pod 的配置文件,其拥有一个请求 1000 GiB 内存的容器,这应该超过了你集群中任何节点的容量。
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-2
namespace: waite
spec:
containers:
- name: memory-demo-3-ctr
image: polinux/stress
resources:
requests:
memory: "1000Gi"
limits:
memory: "1000Gi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
D:\k8s>kubectl apply -f memory-request-limit.yaml --namespace=waite
pod/memory-demo-2 created
D:\k8s>kubectl get pod -n waite
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 Pending 0 3s
# 输出结果显示:Pod 处于 PENDING 状态。 这意味着,该 Pod 没有被调度至任何节点上运行,并且它会无限期的保持该状态:
D:\k8s>kubectl describe pod memory-demo-2 --namespace=waite
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 49s default-scheduler 0/1 nodes are available: 1 Insufficient memory. no new claims to deallocate, preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling.
# 输出结果显示:由于节点内存不足,该容器无法被调度:
如果你没有为一个容器指定内存限制,则自动遵循以下情况之一:
- 容器可无限制地使用内存。容器可以使用其所在节点所有的可用内存, 进而可能导致该节点调用 OOM Killer。 此外,如果发生 OOM Kill,没有资源限制的容器将被杀掉的可行性更大。
- 运行的容器所在命名空间有默认的内存限制,那么该容器会被自动分配默认限制。 集群管理员可用使用 LimitRange 来指定默认的内存限制
删除命名空间。下面的命令会删除你根据这个任务创建的所有 Pod:
kubectl delete namespace mem-example
为容器以及 Pods 分配 CPU 和内存资源
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
namespace: waite
spec:
containers:
- name: cpu-demo-ctr
image: polinux/stress
resources:
limits:
cpu: "1"
requests:
cpu: "0.5"
args:
- -cpus
- "2"
D:\k8s>kubectl get pod cpu-demo --namespace=waite
NAME READY STATUS RESTARTS AGE
cpu-demo 1/1 Running 0 2m46s
D:\k8s>kubectl get pod cpu-demo --output=yaml --namespace=waite
spec:
containers:
- args:
- -cpus
- "2"
image: vish/stress
imagePullPolicy: Always
name: cpu-demo-ctr
resources:
limits:
cpu: "1"
requests:
cpu: 500m
# 输出显示 Pod 中的一个容器的 CPU 请求为 500 milliCPU,并且 CPU 限制为 1 个 CPU。
D:\k8s>kubectl top pod cpu-demo --namespace=waite
NAME CPU(cores) MEMORY(bytes)
cpu-demo 1000m 0Mi
# 此示例输出显示 Pod 使用的是 1000 M,小于等于限制的 1 GPU, 如果你的容器在只有 1 个 CPU 的节点上运行,则容器无论为容器指定的 CPU 限制如何, 都不能使用超过 1 个 CPU。
如果不指定 CPU 限制
容器在可以使用的 CPU 资源上没有上限。因而可以使用所在节点上所有的可用 CPU 资源。
容器在具有默认 CPU 限制的名字空间中运行,系统会自动为容器设置默认限制。 集群管理员可以使用 LimitRange 指定 CPU 限制的默认值。如果你设置了 CPU 限制但未设置 CPU 请求
如果你为容器指定了 CPU 限制值但未为其设置 CPU 请求,Kubernetes 会自动为其 设置与 CPU 限制相同的 CPU 请求值。类似的,如果容器设置了内存限制值但未设置 内存请求值,Kubernetes 也会为其设置与内存限制值相同的内存请求
配置 Pod 以使用卷进行存储
在本练习中,你将创建一个运行 Pod,该 Pod 仅运行一个容器并拥有一个类型为 emptyDir 的卷, 在整个 Pod 生命周期中一直存在,即使 Pod 中的容器被终止和重启。以下是 Pod 的配置:
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: {}
emptyDir卷 这种卷的生命周期是 与 Pod 绑定 的:
- Pod 存在 → 卷存在
- Pod 被删除或重建 → 卷被清空,数据永久丢失
配置 Pod 以使用 PersistentVolume 作为存储
打开集群中的某个节点的 Shell。 如何打开 Shell 取决于集群的设置。 例如,如果你正在使用 Minikube,那么可以通过输入 minikube ssh 来打开节点的 Shell。
在该节点的 Shell 中,创建一个 /mnt/data 目录:
# 这里假定你的节点使用 "sudo" 来以超级用户角色执行命令
sudo mkdir /mnt/data
在 /mnt/data 目录中创建一个 index.html 文件:
# 这里再次假定你的节点使用 "sudo" 来以超级用户角色执行命令
sudo sh -c "echo 'Hello from Kubernetes storage' > /mnt/data/index.html"
说明:
如果你的节点使用某工具而不是 sudo 来完成超级用户访问,你可以将上述命令中的 sudo 替换为该工具的名称。
测试 index.html 文件确实存在:
cat /mnt/data/index.html
输出应该是:
Hello from Kubernetes storage
现在你可以关闭节点的 Shell 了, 后续我们会将 pods 绑定到该卷上。
在本练习中,你将创建一个 hostPath 类型的 PersistentVolume。 Kubernetes 支持用于在单节点集群上开发和测试的 hostPath 类型的 PersistentVolume。 hostPath 类型的 PersistentVolume 使用节点上的文件或目录来模拟网络附加存储。
在生产集群中,你不会使用 hostPath。 集群管理员会提供网络存储资源,比如 Google Compute Engine 持久盘卷、NFS 共享卷或 Amazon Elastic Block Store 卷。 集群管理员还可以使用 StorageClass 来设置 动态制备存储。
下面是 hostPath PersistentVolume 的配置文件:
apiVersion: v1
kind: PersistentVolume
metadata:
name: task-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
此配置文件指定卷位于集群节点上的 /mnt/data 路径。 其配置还指定了卷的容量大小为 10 GB,访问模式为 ReadWriteOnce, 这意味着该卷可以被单个节点以读写方式安装。 此配置文件还在 PersistentVolume 中定义了
StorageClass 的名称为 manual。 它将用于将 PersistentVolumeClaim 的请求绑定到此 PersistentVolume。
为了简化,本示例采用了 ReadWriteOnce 访问模式。然而对于生产环境, Kubernetes 项目建议改用 ReadWriteOncePod 访问模式。
创建 PersistentVolume:
kubectl apply -f https://k8s.io/examples/pods/storage/pv-volume.yaml
查看 PersistentVolume 的信息:
kubectl get pv task-pv-volume
输出结果显示该 PersistentVolume 的状态(STATUS)为 Available。 这意味着它还没有被绑定给 PersistentVolumeClaim。
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
task-pv-volume 10Gi RWO Retain Available manual
下一步是创建一个 PersistentVolumeClaim。 Pod 使用 PersistentVolumeClaim 来请求物理存储。 在本练习中,你将创建一个 PersistentVolumeClaim,它请求至少 3 GB 容量的卷, 该卷一次最多可以为一个节点提供读写访问。
下面是 PersistentVolumeClaim 的配置文件:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: task-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
Kubernetes 文档 任务 配置 Pods 和容器 配置 Pod 以使用 PersistentVolume 作为存储
配置 Pod 以使用 PersistentVolume 作为存储
本文将向你介绍如何配置 Pod 使用 PersistentVolumeClaim 作为存储。 以下是该过程的总结:
- 你作为集群管理员创建由物理存储支持的 PersistentVolume。你不会将该卷与任何 Pod 关联。
- 你现在以开发人员或者集群用户的角色创建一个 PersistentVolumeClaim, 它将自动绑定到合适的 PersistentVolume。
- 你创建一个使用以上 PersistentVolumeClaim 作为存储的 Pod。
在你的节点上创建一个 index.html 文件
打开集群中的某个节点的 Shell。 如何打开 Shell 取决于集群的设置。 例如,如果你正在使用 Minikube,那么可以通过输入 minikube ssh 来打开节点的 Shell。
在该节点的 Shell 中,创建一个 /mnt/data 目录:
# 这里假定你的节点使用 "sudo" 来以超级用户角色执行命令
sudo mkdir /mnt/data
在 /mnt/data 目录中创建一个 index.html 文件:
# 这里再次假定你的节点使用 "sudo" 来以超级用户角色执行命令
sudo sh -c "echo 'Hello from Kubernetes storage' > /mnt/data/index.html"
说明:
如果你的节点使用某工具而不是 sudo 来完成超级用户访问,你可以将上述命令中的 sudo 替换为该工具的名称。
测试 index.html 文件确实存在:
cat /mnt/data/index.html
输出应该是:
Hello from Kubernetes storage
现在你可以关闭节点的 Shell 了。
创建 PersistentVolume
在本练习中,你将创建一个 hostPath 类型的 PersistentVolume。 Kubernetes 支持用于在单节点集群上开发和测试的 hostPath 类型的 PersistentVolume。 hostPath 类型的 PersistentVolume 使用节点上的文件或目录来模拟网络附加存储。
在生产集群中,你不会使用 hostPath。 集群管理员会提供网络存储资源,比如 Google Compute Engine 持久盘卷、NFS 共享卷或 Amazon Elastic Block Store 卷。 集群管理员还可以使用 StorageClass 来设置 动态制备存储。
下面是 hostPath PersistentVolume 的配置文件:
apiVersion: v1
kind: PersistentVolume
metadata:
name: task-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
此配置文件指定卷位于集群节点上的 /mnt/data 路径。 其配置还指定了卷的容量大小为 10 GB,访问模式为 ReadWriteOnce, 这意味着该卷可以被单个节点以读写方式安装。 此配置文件还在 PersistentVolume 中定义了
StorageClass 的名称为 manual。 它将用于将 PersistentVolumeClaim 的请求绑定到此 PersistentVolume。
为了简化,本示例采用了 ReadWriteOnce 访问模式。然而对于生产环境, Kubernetes 项目建议改用 ReadWriteOncePod 访问模式。
创建 PersistentVolume:
kubectl apply -f https://k8s.io/examples/pods/storage/pv-volume.yaml
查看 PersistentVolume 的信息:
kubectl get pv task-pv-volume
输出结果显示该 PersistentVolume 的状态(STATUS)为 Available。 这意味着它还没有被绑定给 PersistentVolumeClaim。
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
task-pv-volume 10Gi RWO Retain Available manual 4s
创建 PersistentVolumeClaim
下一步是创建一个 PersistentVolumeClaim。 Pod 使用 PersistentVolumeClaim 来请求物理存储。 在本练习中,你将创建一个 PersistentVolumeClaim,它请求至少 3 GB 容量的卷, 该卷一次最多可以为一个节点提供读写访问。
下面是 PersistentVolumeClaim 的配置文件:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: task-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
创建 PersistentVolumeClaim:
kubectl apply -f https://k8s.io/examples/pods/storage/pv-claim.yaml
创建 PersistentVolumeClaim 之后,Kubernetes 控制平面将查找满足申领要求的 PersistentVolume。 如果控制平面找到具有相同 StorageClass 的适当的 PersistentVolume, 则将 PersistentVolumeClaim 绑定到该 PersistentVolume 上。
再次查看 PersistentVolume 信息:
kubectl get pv task-pv-volume
现在输出的 STATUS 为 Bound。
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
task-pv-volume 10Gi RWO Retain Bound default/task-pv-claim manual 2m
查看 PersistentVolumeClaim:
kubectl get pvc task-pv-claim
输出结果表明该 PersistentVolumeClaim 绑定了你的 PersistentVolume task-pv-volume。
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
task-pv-claim Bound task-pv-volume 10Gi RWO manual 30s
各自角色
① Provision → ② Binding → ③ Using → ④ Releasing → ⑤ Reclaiming① 供给(Provision) - 静态:管理员先建好一批 PV 放着。 - 动态:没有合适 PV 时,PVC 会触发 CSI 驱动即刻创建一个 PV(
storageClassName不为空)。② 绑定(Binding) - Scheduler 持续 watch,一旦找到「最闲且字段匹配」的 PV,立即把
pv.spec.claimRef写上 PVC 名字,一对一互锁,别的 PVC 再也抢不到。③ 使用(Using) - Pod 通过
persistentVolumeClaim字段挂载,容器里看到的就是 PV 背后的真实存储路径。
- 此时就算 Pod 重建、调度到别的节点,只要 PVC 在,数据就跟着走。
④ 释放(Releasing) - 用户
kubectl delete pvc task-pvc;PV 状态变成Released,但数据还在(取决于回收策略)。⑤ 回收(Reclaiming) - Retain:人工清理,
pv.status.phase=Released,需要管理员手动kubectl delete pv并到存储后端删数据。 - Delete:CSI 自动把后端卷一起删掉(云盘常用)。 - Recycle(已废弃):曾用rm -rf清目录。
| 对象 | 谁创建 | 作用 | 类比 |
|---|---|---|---|
| PersistentVolume (PV) | 集群管理员(或 CSI 自动供给) | 提供一段真实的存储资源 | 楼盘 |
| PersistentVolumeClaim (PVC) | 应用开发者(用户) | 申请一段存储,声明容量、访问模式、Storage | 购房合同创建 Pod |
下一步是创建一个使用你的 PersistentVolumeClaim 作为存储卷的 Pod。
下面是此 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
注意 Pod 的配置文件指定了 PersistentVolumeClaim,但没有指定 PersistentVolume。 对 Pod 而言,PersistentVolumeClaim 就是一个存储卷。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/storage/pv-pod.yaml
检查 Pod 中的容器是否运行正常:
kubectl get pod task-pv-pod
打开一个 Shell 访问 Pod 中的容器:
kubectl exec -it task-pv-pod -- /bin/bash
在 Shell 中,验证 Nginx 是否正在从 hostPath 卷提供 index.html 文件:
# 一定要在上一步 "kubectl exec" 所返回的 Shell 中执行下面三个命令
apt update
apt install curl
curl http://localhost/
输出结果是你之前写到 hostPath 卷中的 index.html 文件中的内容:
Hello from Kubernetes storage
如果你看到此消息,则证明你已经成功地配置了 Pod 使用 PersistentVolumeClaim 的存储。
配置 Pod 使用投射卷作存储
本练习中,你将使用本地文件来创建用户名和密码
Secret, 然后创建运行一个容器的 Pod, 该 Pod 使用
projected 卷将 Secret 挂载到相同的路径下。
下面是 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: test-projected-volume
spec:
containers:
- name: test-projected-volume
image: busybox:1.28
args:
- sleep
- "86400"
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: user
- secret:
name: pass
创建 Secret:
# 创建包含用户名和密码的文件: echo -n "admin" > ./username.txt echo -n "1f2d1e2e67df" > ./password.txt # 在 Secret 中引用上述文件 kubectl create secret generic user --from-file=./username.txt kubectl create secret generic pass --from-file=./password.txt创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/storage/projected.yaml确认 Pod 中的容器运行正常,然后监视 Pod 的变化:
kubectl get --watch pod test-projected-volume输出结果和下面类似:
NAME READY STATUS RESTARTS AGE test-projected-volume 1/1 Running 0 14s在另外一个终端中,打开容器的 shell:
kubectl exec -it test-projected-volume -- /bin/sh在 shell 中,确认
projected-volume目录包含你的投射源:/ # ls /projected-volume/ password.txt username.txt / # cat /projected-volume/username.txt -n "admin"
从私有仓库拉取镜像
在个人电脑上,要想拉取私有镜像必须在镜像仓库上进行身份验证。
使用 docker 命令工具来登录到 Docker Hub。 更多详细信息,请查阅
Docker ID accounts 中的 log in 部分。
docker login
当出现提示时,输入你的 Docker ID 和登录凭据(访问令牌或 Docker ID 的密码)。
登录过程会创建或更新保存有授权令牌的 config.json 文件。 查看
Kubernetes 如何解析这个文件。
查看 config.json 文件:
cat ~/.docker/config.json
输出结果包含类似于以下内容的部分:
{
"auths": {
"https://index.docker.io/v1/": {
"auth": "c3R...zE2"
}
}
}
如果使用 Docker 凭据仓库,则不会看到 auth 条目,看到的将是以仓库名称作为值的 credsStore 条目。 在这种情况下,你可以直接创建一个 Secret。 请参阅
在命令行上提供凭据来创建 Secret。
Kubernetes 集群使用 kubernetes.io/dockerconfigjson 类型的 Secret 来通过镜像仓库的身份验证,进而提取私有镜像。
如果你已经运行了 docker login 命令,你可以复制该镜像仓库的凭据到 Kubernetes:
kubectl create secret generic regcred \
--from-file=.dockerconfigjson=<path/to/.docker/config.json> \
--type=kubernetes.io/dockerconfigjson
如果你需要更多的设置(例如,为新 Secret 设置名字空间或标签), 则可以在存储 Secret 之前对它进行自定义。 请务必:
- 将 data 项中的名称设置为
.dockerconfigjson - 使用 base64 编码方法对 Docker 配置文件进行编码,然后粘贴该字符串的内容,作为字段
data[".dockerconfigjson"]的值 - 将
type设置为kubernetes.io/dockerconfigjson
示例:
apiVersion: v1
kind: Secret
metadata:
name: myregistrykey
namespace: awesomeapps
data:
.dockerconfigjson: UmVhbGx5IHJlYWxseSByZWVlZWVlZWVlZWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGx5eXl5eXl5eXl5eXl5eXl5eXl5eSBsbGxsbGxsbGxsbGxsbG9vb29vb29vb29vb29vb29vb29vb29vb29vb25ubm5ubm5ubm5ubm5ubm5ubm5ubm5ubmdnZ2dnZ2dnZ2dnZ2dnZ2dnZ2cgYXV0aCBrZXlzCg==
type: kubernetes.io/dockerconfigjson
如果你收到错误消息:error: no objects passed to create, 这可能意味着 base64 编码的字符串是无效的。如果你收到类似 Secret "myregistrykey" is invalid: data[.dockerconfigjson]: invalid value ... 的错误消息,则表示数据中的 base64 编码字符串已成功解码, 但无法解析为 .docker/config.json 文件。
创建 Secret,命名为 regcred:
kubectl create secret docker-registry regcred \
--docker-server=<你的镜像仓库服务器> \
--docker-username=<你的用户名> \
--docker-password=<你的密码> \
--docker-email=<你的邮箱地址>
在这里:
<your-registry-server>是你的私有 Docker 仓库全限定域名(FQDN)。 DockerHub 使用https://index.docker.io/v1/。<your-name>是你的 Docker 用户名。<your-pword>是你的 Docker 密码。<your-email>是你的 Docker 邮箱。
这样你就成功地将集群中的 Docker 凭据设置为名为 regcred 的 Secret。
在命令行上键入 Secret 可能会将它们存储在你的 Shell 历史记录中而不受保护, 并且这些 Secret 信息也可能在 kubectl 运行期间对你 PC 上的其他用户可见。
了解你创建的 regcred Secret 的内容,可以用 YAML 格式进行查看:
kubectl get secret regcred --output=yaml
输出和下面类似:
apiVersion: v1
kind: Secret
metadata:
...
name: regcred
...
data:
.dockerconfigjson: eyJodHRwczovL2luZGV4L ... J0QUl6RTIifX0=
type: kubernetes.io/dockerconfigjson
.dockerconfigjson 字段的值是 Docker 凭据的 base64 表示。
要了解 dockerconfigjson 字段中的内容,请将 Secret 数据转换为可读格式:
kubectl get secret regcred --output="jsonpath={.data.\.dockerconfigjson}" | base64 --decode
输出和下面类似:
{"auths":{"your.private.registry.example.com":{"username":"janedoe","password":"xxxxxxxxxxx","email":"jdoe@example.com","auth":"c3R...zE2"}}}
要了解 auth 字段中的内容,请将 base64 编码过的数据转换为可读格式:
echo "c3R...zE2" | base64 --decode
输出结果中,用户名和密码用 : 链接,类似下面这样:
janedoe:xxxxxxxxxxx
注意,Secret 数据包含与本地 ~/.docker/config.json 文件类似的授权令牌。
这样你就已经成功地将 Docker 凭据设置为集群中的名为 regcred 的 Secret。
下面是一个 Pod 配置清单示例,该示例中 Pod 需要访问你的 Docker 凭据 regcred:
apiVersion: v1
kind: Pod
metadata:
name: private-reg
spec:
containers:
- name: private-reg-container
image: <your-private-image>
imagePullSecrets:
- name: regcred
将上述文件下载到你的计算机中:
curl -L -o my-private-reg-pod.yaml https://k8s.io/examples/pods/private-reg-pod.yaml
在 my-private-reg-pod.yaml 文件中,使用私有仓库的镜像路径替换 <your-private-image>,例如:
your.private.registry.example.com/janedoe/jdoe-private:v1
要从私有仓库拉取镜像,Kubernetes 需要凭据。 配置文件中的 imagePullSecrets 字段表明 Kubernetes 应该通过名为 regcred 的 Secret 获取凭据。
创建使用了你的 Secret 的 Pod,并检查它是否正常运行:
kubectl apply -f my-private-reg-pod.yaml
kubectl get pod private-reg
要为 Pod(或 Deployment,或其他有 Pod 模板的对象)使用镜像拉取 Secret, 你需要确保合适的 Secret 确实存在于正确的名字空间中。 要使用的是你定义 Pod 时所用的名字空间。
此外,如果 Pod 启动失败,状态为 ImagePullBackOff,查看 Pod 事件:
kubectl describe pod private-reg
如果你看到一个原因设为 FailedToRetrieveImagePullSecret 的事件, 那么 Kubernetes 找不到指定名称(此例中为 regcred)的 Secret。
确保你指定的 Secret 存在,并且其名称拼写正确。
Events:
... Reason ... Message
------ -------
... FailedToRetrieveImagePullSecret ... Unable to retrieve some image pull secrets (<regcr
配置存活、就绪和启动探针
kubelet 使用存活探针来确定什么时候要重启容器。 例如,存活探针可以探测到应用死锁(应用在运行,但是无法继续执行后面的步骤)情况。 重启这种状态下的容器有助于提高应用的可用性,即使其中存在缺陷。
存活探针的常见模式是为就绪探针使用相同的低成本 HTTP 端点,但具有更高的 failureThreshold。 这样可以确保在硬性终止 Pod 之前,将观察到 Pod 在一段时间内处于非就绪状态。
kubelet 使用就绪探针可以知道容器何时准备好接受请求流量。 这种信号的一个用途就是控制哪个 Pod 作为 Service 的后端。 当 Pod 的 Ready
状况 为 true 时,Pod 被认为是就绪的。若 Pod 未就绪,会被从 Service 的负载均衡器中剔除。 当 Pod 所在节点的 Ready 状况不为 true 时、当 Pod 的某个 readinessGates 为 false 时,或者当 Pod 中有任何一个容器未就绪时,Pod 的 Ready 状况为 false。
kubelet 使用启动探针来了解应用容器何时启动。 如果配置了这类探针,存活探针和就绪探针在启动探针成功之前不会启动,从而确保存活探针或就绪探针不会影响应用的启动。 启动探针可以用于对慢启动容器进行存活性检测,避免它们在启动运行之前就被杀掉。
存活探针是一种从应用故障中恢复的强劲方式,但应谨慎使用。 你必须仔细配置存活探针,确保它能真正标示出不可恢复的应用故障,例如死锁。
错误的存活探针可能会导致级联故障。 这会导致在高负载下容器重启;例如由于应用无法扩展,导致客户端请求失败;以及由于某些 Pod 失败而导致剩余 Pod 的工作负载增加。了解就绪探针和存活探针之间的区别, 以及何时为应用配置使用它们非常重要。
许多长时间运行的应用最终会进入损坏状态,除非重新启动,否则无法被恢复。 Kubernetes 提供了存活探针来发现并处理这种情况。
在本练习中,你会创建一个 Pod,其中运行一个基于 registry.k8s.io/busybox:1.27.2 镜像的容器。 下面是这个 Pod 的配置文件。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: registry.k8s.io/busybox:1.27.2
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
在这个配置文件中,可以看到 Pod 中只有一个 Container。 periodSeconds 字段指定了 kubelet 应该每 5 秒执行一次存活探测。 initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 5 秒。 kubelet 在容器内执行命令 cat /tmp/healthy 来进行探测。 如果命令执行成功并且返回值为 0,kubelet 就会认为这个容器是健康存活的。 如果这个命令返回非 0 值,kubelet 会杀死这个容器并重新启动它。
当容器启动时,执行如下的命令:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600"
这个容器生命的前 30 秒,/tmp/healthy 文件是存在的。 所以在这最开始的 30 秒内,执行命令 cat /tmp/healthy 会返回成功代码。 30 秒之后,执行命令 cat /tmp/healthy 就会返回失败代码。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/probe/exec-liveness.yaml
在 30 秒内,查看 Pod 的事件:
kubectl describe pod liveness-exec
输出结果表明还没有存活探针失败:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11s default-scheduler Successfully assigned default/liveness-exec to node01
Normal Pulling 9s kubelet, node01 Pulling image "registry.k8s.io/busybox:1.27.2"
Normal Pulled 7s kubelet, node01 Successfully pulled image "registry.k8s.io/busybox:1.27.2"
Normal Created 7s kubelet, node01 Created container liveness
Normal Started 7s kubelet, node01 Started container liveness
35 秒之后,再来看 Pod 的事件:
kubectl describe pod liveness-exec
在输出结果的最下面,有信息显示存活探针失败了,这个失败的容器被杀死并且被重建了。
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 57s default-scheduler Successfully assigned default/liveness-exec to node01
Normal Pulling 55s kubelet, node01 Pulling image "registry.k8s.io/busybox:1.27.2"
Normal Pulled 53s kubelet, node01 Successfully pulled image "registry.k8s.io/busybox:1.27.2"
Normal Created 53s kubelet, node01 Created container liveness
Normal Started 53s kubelet, node01 Started container liveness
Warning Unhealthy 10s (x3 over 20s) kubelet, node01 Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Normal Killing 10s kubelet, node01 Container liveness failed liveness probe, will be restarted
再等 30 秒,确认这个容器被重启了:
kubectl get pod liveness-exec
输出结果显示 RESTARTS 的值增加了 1。 请注意,一旦失败的容器恢复为运行状态,RESTARTS 计数器就会增加 1:
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
另外一种类型的存活探测方式是使用 HTTP GET 请求。 下面是一个 Pod 的配置文件,其中运行一个基于 registry.k8s.io/e2e-test-images/agnhost 镜像的容器。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/e2e-test-images/agnhost:2.40
args:
- liveness
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
在这个配置文件中,你可以看到 Pod 也只有一个容器。 periodSeconds 字段指定了 kubelet 每隔 3 秒执行一次存活探测。 initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 3 秒。 kubelet 会向容器内运行的服务(服务在监听 8080 端口)发送一个 HTTP GET 请求来执行探测。 如果服务器上 /healthz 路径下的处理程序返回成功代码,则 kubelet 认为容器是健康存活的。 如果处理程序返回失败代码,则 kubelet 会杀死这个容器并将其重启。
返回大于或等于 200 并且小于 400 的任何代码都标示成功,其它返回代码都标示失败。
你可以访问
server.go 阅读服务的源码。 容器存活期间的最开始 10 秒中,/healthz 处理程序返回 200 的状态码。 之后处理程序返回 500 的状态码。
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
duration := time.Now().Sub(started)
if duration.Seconds() > 10 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write([]byte("ok"))
}
})
kubelet 在容器启动之后 3 秒开始执行健康检查。所以前几次健康检查都是成功的。 但是 10 秒之后,健康检查会失败,并且 kubelet 会杀死容器再重新启动容器。
创建一个 Pod 来测试 HTTP 的存活检测:
kubectl apply -f https://k8s.io/examples/pods/probe/http-liveness.yaml
10 秒之后,通过查看 Pod 事件来确认存活探针已经失败,并且容器被重新启动了。
kubectl describe pod liveness-http
在 1.13 之后的版本中,设置本地的 HTTP 代理环境变量不会影响 HTTP 的存活探测。
第三种类型的存活探测是使用 TCP 套接字。 使用这种配置时,kubelet 会尝试在指定端口和容器建立套接字链接。 如果能建立连接,这个容器就被看作是健康的,如果不能则这个容器就被看作是有问题的。
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: registry.k8s.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
如你所见,TCP 检测的配置和 HTTP 检测非常相似。 下面这个例子同时使用就绪探针和存活探针。kubelet 会在容器启动 15 秒后运行第一次存活探测。 此探测会尝试连接 goproxy 容器的 8080 端口。 如果此存活探测失败,容器将被重启。kubelet 将继续每隔 10 秒运行一次这种探测。
除了存活探针,这个配置还包括一个就绪探针。 kubelet 会在容器启动 15 秒后运行第一次就绪探测。 与存活探测类似,就绪探测会尝试连接 goproxy 容器的 8080 端口。 如果就绪探测失败,Pod 将被标记为未就绪,且不会接收来自任何服务的流量。
要尝试 TCP 存活检测,运行以下命令创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/probe/tcp-liveness-readiness.yaml
15 秒之后,通过查看 Pod 事件来检测存活探针:
kubectl describe pod goproxy
定义 gRPC 存活探针
如果你的应用实现了 gRPC 健康检查协议, 这个例子展示了如何配置 Kubernetes 以将其用于应用的存活性检查。 类似地,你可以配置就绪探针和启动探针。
下面是一个示例清单:
apiVersion: v1
kind: Pod
metadata:
name: etcd-with-grpc
spec:
containers:
- name: etcd
image: registry.k8s.io/etcd:3.5.1-0
command: [ "/usr/local/bin/etcd", "--data-dir", "/var/lib/etcd", "--listen-client-urls", "http://0.0.0.0:2379", "--advertise-client-urls", "http://127.0.0.1:2379", "--log-level", "debug"]
ports:
- containerPort: 2379
livenessProbe:
grpc:
port: 2379
initialDelaySeconds: 10
要使用 gRPC 探针,必须配置 port 属性。 如果要区分不同类型的探针和不同功能的探针,可以使用 service 字段。 你可以将 service 设置为 liveness,并使你的 gRPC 健康检查端点对该请求的响应与将 service 设置为 readiness 时不同。 这使你可以使用相同的端点进行不同类型的容器健康检查而不是监听两个不同的端口。 如果你想指定自己的自定义服务名称并指定探测类型,Kubernetes 项目建议你使用使用一个可以关联服务和探测类型的名称来命名。 例如:myservice-liveness(使用 - 作为分隔符)。
与 HTTP 或 TCP 探针不同,gRPC 探测不能按名称指定健康检查端口, 也不能自定义主机名。
配置问题(例如:错误的 port 或 service、未实现健康检查协议) 都被认作是探测失败,这一点与 HTTP 和 TCP 探针类似。
kubectl apply -f https://k8s.io/examples/pods/probe/grpc-liveness.yaml
15 秒钟之后,查看 Pod 事件确认存活性检查并未失败:
kubectl describe pod etcd-with-grpc
当使用 gRPC 探针时,需要注意以下一些技术细节:
- 这些探针运行时针对的是 Pod 的 IP 地址或其主机名。 请一定配置你的 gRPC 端点使之监听于 Pod 的 IP 地址之上。
- 这些探针不支持任何身份认证参数(例如
-tls)。 - 对于内置的探针而言,不存在错误代码。所有错误都被视作探测失败。
- 如果
ExecProbeTimeout特性门控被设置为false,则grpc-health-probe不会考虑timeoutSeconds设置状态(默认值为1s), 而内置探针则会在超时时返回失败。
使用命名端口
对于 HTTP 和 TCP 存活检测可以使用命名的
port (gRPC 探针不支持使用命名端口)。
例如:
ports:
- name: liveness-port
containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
使用启动探针保护慢启动容器
有时候,会有一些现有的应用在启动时需要较长的初始化时间。 在这种情况下,若要不影响对死锁作出快速响应的探测,设置存活探测参数是要技巧的。 解决办法是使用相同的命令来设置启动探测,针对 HTTP 或 TCP 检测,可以通过将 failureThreshold * periodSeconds 参数设置为足够长的时间来应对最糟糕情况下的启动时间。
这样,前面的例子就变成了:
ports:
- name: liveness-port
containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 10
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30
periodSeconds: 10
幸亏有启动探测,应用将会有最多 5 分钟(30 * 10 = 300s)的时间来完成其启动过程。 一旦启动探测成功一次,存活探测任务就会接管对容器的探测,对容器死锁作出快速响应。 如果启动探测一直没有成功,容器会在 300 秒后被杀死,并且根据 restartPolicy 来执行进一步处置。
定义就绪探针
有时候,应用会暂时性地无法为请求提供服务。 例如,应用在启动时可能需要加载大量的数据或配置文件,或是启动后要依赖等待外部服务。 在这种情况下,既不想杀死应用,也不想给它发送请求。 Kubernetes 提供了就绪探针来发现并缓解这些情况。 容器所在 Pod 上报还未就绪的信息,并且不接受通过 Kubernetes Service 的流量。
就绪探针在容器的整个生命周期中保持运行状态。
存活探针与就绪性探针相互间不等待对方成功。 如果要在执行就绪性探针之前等待,应该使用 initialDelaySeconds 或 startupProbe。
就绪探针的配置和存活探针的配置相似。 唯一区别就是要使用 readinessProbe 字段,而不是 livenessProbe 字段。
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
HTTP 和 TCP 的就绪探针配置也和存活探针的配置完全相同。
就绪和存活探测可以在同一个容器上并行使用。 两者共同使用,可以确保流量不会发给还未就绪的容器,当这些探测失败时容器会被重新启动。
配置探针
Probe 有很多配置字段,可以使用这些字段精确地控制启动、存活和就绪检测的行为:
initialDelaySeconds:容器启动后要等待多少秒后才启动启动、存活和就绪探针。 如果定义了启动探针,则存活探针和就绪探针的延迟将在启动探针已成功之后才开始计算。 在某些较旧的 Kubernetes 版本中,如果periodSeconds的值大于initialDelaySeconds, 则initialDelaySeconds将被忽略。然而,在当前版本中,initialDelaySeconds总是被遵守, 并且探测不会在这个初始延迟之前开始。默认是 0 秒,最小值是 0。periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。 当容器未就绪时,ReadinessProbe可能会在除配置的periodSeconds间隔以外的时间执行。这是为了让 Pod 更快地达到可用状态。timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。successThreshold:探针在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1。failureThreshold:探针连续失败了failureThreshold次之后, Kubernetes 认为总体上检查已失败:容器状态未就绪、不健康、不活跃。 默认值为 3,最小值为 1。 对于启动探针或存活探针而言,如果至少有failureThreshold个探针已失败, Kubernetes 会将容器视为不健康并为这个特定的容器触发重启操作。 kubelet 遵循该容器的terminationGracePeriodSeconds设置。 对于失败的就绪探针,kubelet 继续运行检查失败的容器,并继续运行更多探针; 因为检查失败,kubelet 将 Pod 的Ready状况设置为false。terminationGracePeriodSeconds:为 kubelet 配置从为失败的容器触发终止操作到强制容器运行时停止该容器之前等待的宽限时长。 默认值是继承 Pod 级别的terminationGracePeriodSeconds值(如果不设置则为 30 秒),最小值为 1。 更多细节请参见 探针级别terminationGracePeriodSeconds。
如果就绪态探针的实现不正确,可能会导致容器中进程的数量不断上升。 如果不对其采取措施,很可能导致资源枯竭的状况。
HTTP 探测
HTTP Probe 允许针对 httpGet 配置额外的字段:
host:连接使用的主机名,默认是 Pod 的 IP。也可以在 HTTP 头中设置 “Host” 来代替。scheme:用于设置连接主机的方式(HTTP 还是 HTTPS)。默认是 “HTTP”。path:访问 HTTP 服务的路径。默认值为 “/"。httpHeaders:请求中自定义的 HTTP 头。HTTP 头字段允许重复。port:访问容器的端口号或者端口名。如果数字必须在 1~65535 之间。
对于 HTTP 探测,kubelet 发送一个 HTTP 请求到指定的端口和路径来执行检测。 除非 httpGet 中的 host 字段设置了,否则 kubelet 默认是给 Pod 的 IP 地址发送探测。 如果 scheme 字段设置为了 HTTPS,kubelet 会跳过证书验证发送 HTTPS 请求。 大多数情况下,不需要设置 host 字段。 这里有个需要设置 host 字段的场景,假设容器监听 127.0.0.1,并且 Pod 的 hostNetwork 字段设置为了 true。那么 httpGet 中的 host 字段应该设置为 127.0.0.1。 可能更常见的情况是如果 Pod 依赖虚拟主机,你不应该设置 host 字段,而是应该在 httpHeaders 中设置 Host。
针对 HTTP 探针,kubelet 除了必需的 Host 头部之外还发送两个请求头部字段:
User-Agent:默认值是kube-probe/1.34,其中1.34是 kubelet 的版本号。Accept:默认值*/*。
你可以通过为探测设置 httpHeaders 来重载默认的头部字段值。例如:
livenessProbe:
httpGet:
httpHeaders:
- name: Accept
value: application/json
startupProbe:
httpGet:
httpHeaders:
- name: User-Agent
value: MyUserAgent
你也可以通过将这些头部字段定义为空值,从请求中去掉这些头部字段。
livenessProbe:
httpGet:
httpHeaders:
- name: Accept
value: ""
startupProbe:
httpGet:
httpHeaders:
- name: User-Agent
value: ""
当 kubelet 使用 HTTP 探测 Pod 时,仅当重定向到同一主机时,它才会遵循重定向。 如果 kubelet 在探测期间收到 11 个或更多重定向,则认为探测成功并创建相关事件:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 29m default-scheduler Successfully assigned default/httpbin-7b8bc9cb85-bjzwn to daocloud
Normal Pulling 29m kubelet Pulling image "docker.io/kennethreitz/httpbin"
Normal Pulled 24m kubelet Successfully pulled image "docker.io/kennethreitz/httpbin" in 5m12.402735213s
Normal Created 24m kubelet Created container httpbin
Normal Started 24m kubelet Started container httpbin
Warning ProbeWarning 4m11s (x1197 over 24m) kubelet Readiness probe warning: Probe terminated redirects
如果 kubelet 收到主机名与请求不同的重定向,则探测结果将被视为成功,并且 kubelet 将创建一个事件来报告重定向失败。
在处理 httpGet 探针时,kubelet 在读取了 10KiB 的响应体后会停止读取。 探针的成功与否仅由响应状态码决定,此状态码位于响应头中。
如果你探测一个返回的响应体大于 10KiB 的端点,kubelet 仍然会根据状态码将探针标记为成功, 但在达到 10KiB 限制后关闭连接。这种突然的关闭可能导致 connection reset by peer 或 broken pipe error 出现在你的应用程序日志中,这可能难以与合法的网络问题区分。
对于可靠的
httpGet探针,强烈建议使用专用的健康检查端点, 这些端点返回最小的响应体。如果你必须使用具有大量数据负载的现有端点, 可以考虑使用exec探针来执行 HEAD 请求。
TCP 探测
对于 TCP 探测而言,kubelet 在节点上(不是在 Pod 里面)发起探测连接, 这意味着你不能在 host 参数上配置服务名称,因为 kubelet 不能解析服务名称。
探针层面的 terminationGracePeriodSeconds
特性状态: Kubernetes v1.28 [stable]
在 1.25 及以上版本中,用户可以指定一个探针层面的 terminationGracePeriodSeconds 作为探针规约的一部分。 当 Pod 层面和探针层面的 terminationGracePeriodSeconds 都已设置,kubelet 将使用探针层面设置的值。
当设置 terminationGracePeriodSeconds 时,请注意以下事项:
kubelet 始终优先选用探针级别
terminationGracePeriodSeconds字段 (如果它存在于 Pod 上)。如果你已经为现有 Pod 设置了
terminationGracePeriodSeconds字段并且不再希望使用针对每个探针的终止宽限期,则必须删除现有的这类 Pod。
例如:
spec:
terminationGracePeriodSeconds: 3600 # Pod 级别设置
containers:
- name: test
image: ...
ports:
- name: liveness-port
containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 60
# 重载 Pod 级别的 terminationGracePeriodSeconds
terminationGracePeriodSeconds: 60
探针层面的 terminationGracePeriodSeconds 不能用于就绪态探针。 这一设置将被 API 服务器拒绝。